This took me way too long to try and find out how to do. Setting up the teams web hook is simple and straightforward and there are plenty of resources on where to find instructions but what took some time was posting to that web hook with .net code.
There is a simple example using Powershell but no way to show how that translates to .net
$url = "https://outlook.office.com/webhook/{yourwebhookhere}
$body = ConvertTo-JSON @{text = "Gonzo, also known as the great!"}
Invoke-RestMethod -uri $uri -Method Post -body $body -ContentType 'application/json'
That is pretty easy but how about in .net?
The trick is using an HTTP client the only post method is postAsync so you need to either have an Async method or do this trick, this is because nothing will happen if you do not have async methods all the way up the stack.
vb.net
Private Function postToWebHook as string
Dim _uristring As String = "https://outlook.office.com/webhook/{yourwebhookhere}"
Dim jstring As String = "{""text"": ""I just said something!""}"
Dim pload As Payload = New Payload With {.title = "title", .text = "I just created a new header!"}
Dim payloadJson As String = JsonConvert.SerializeObject(pload)
Dim content = New StringContent(payloadJson)
content.Headers.ContentType = New Headers.MediaTypeHeaderValue("application/json")
Dim client As New HttpClient
Dim uri = New Uri(_uristring)
Dim task As Task(Of HttpResponseMessage) = client.PostAsync(uri, content)
return task.Result.ToString
end function
Thursday, March 15, 2018
Wednesday, July 19, 2017
Powershell and file detection in S3 buckets using Get-S3Object
I am currently working on a project where I need to load data into an Amazon S3 bucket, this data comes from various On-Premise sources and eventually feeds into Gainsight. If the data load process fails I need to check and see if there are any files in the configured "error" folder. No files, no problem. When attempting to check this with Powershell I ran into a couple of snags and wanted to provide some of the pain points here.
First you need to go and install the AWS tools for Windows Powershell from here https://aws.amazon.com/powershell/
Make sure you follow the directions exactly to avoid errors and headaches. Once it is running the task of checking for files can begin.
Import-Module AWSPowerShell
$bucket = "xxxx"
$path = "sample/input/error"
$AKey="xxxx"
$SKey="xxxx"
$region = "xxxx"
Set-AWSCredentials -AccessKey $AKey -SecretKey $SKey #-StoreAs For_Move
Initialize-AWSDefaults -ProfileName For_Move -Region $region
$objects = Get-S3Object -BucketName $bucket -Key $path
foreach($object in $objects)
{
#to get rid of the bucket entry you need to set it to '' then make sure you remove that from the listing
#so you need to set it with a replace of the known path
$localfilename = $object.Key -replace $path,''
IF ($localfilename -ne '')
{
Write-host $localfilename
}
}
Import-Module AWSPowerShell -I put this in to make sure the references are loaded correctly
$bucket = "xxxx" - name of your S3 bucket that you are working with
$path = "sample/uploads/errors" - the path in that bucket to where you want to watch
$AKey="xxxx" - your Amazon access key
$SKey="xxxx" - your secret key
Make sure you know your Region, you can specify that in the Get-S3Object call or you can
The most important thing here is that the AWS Get-S3Object does just that - it returns and object, that object may or may not be a file. Interestingly enough when you get the list of objects from the path you will see that it returns the path entry as an object as well. So if I have one file in that path I will see 2 objects, the first is the path the second is the object. So how do you get rid of the path? You can see that I take the object.key and REPLACE the known path string to something that is easy to find, in this case it is an empty string. {$localfilename = $object.Key -replace $path,' '] Then when comparing or looping you can exclude anything that matches that pattern.
First you need to go and install the AWS tools for Windows Powershell from here https://aws.amazon.com/powershell/
Make sure you follow the directions exactly to avoid errors and headaches. Once it is running the task of checking for files can begin.
Import-Module AWSPowerShell
$bucket = "xxxx"
$path = "sample/input/error"
$AKey="xxxx"
$SKey="xxxx"
$region = "xxxx"
Set-AWSCredentials -AccessKey $AKey -SecretKey $SKey #-StoreAs For_Move
Initialize-AWSDefaults -ProfileName For_Move -Region $region
$objects = Get-S3Object -BucketName $bucket -Key $path
foreach($object in $objects)
{
#to get rid of the bucket entry you need to set it to '' then make sure you remove that from the listing
#so you need to set it with a replace of the known path
$localfilename = $object.Key -replace $path,''
IF ($localfilename -ne '')
{
Write-host $localfilename
}
}
Import-Module AWSPowerShell -I put this in to make sure the references are loaded correctly
$bucket = "xxxx" - name of your S3 bucket that you are working with
$path = "sample/uploads/errors" - the path in that bucket to where you want to watch
$AKey="xxxx" - your Amazon access key
$SKey="xxxx" - your secret key
Make sure you know your Region, you can specify that in the Get-S3Object call or you can
The most important thing here is that the AWS Get-S3Object does just that - it returns and object, that object may or may not be a file. Interestingly enough when you get the list of objects from the path you will see that it returns the path entry as an object as well. So if I have one file in that path I will see 2 objects, the first is the path the second is the object. So how do you get rid of the path? You can see that I take the object.key and REPLACE the known path string to something that is easy to find, in this case it is an empty string. {$localfilename = $object.Key -replace $path,' '] Then when comparing or looping you can exclude anything that matches that pattern.
Wednesday, July 27, 2016
SQL Server 2014 SP2 - Clone Database
Looks like there is a new management feature available for SQL Server 2014 SP2 called "clone database". According to Microsoft the goal is to create a database that contains the schema of all the objects and the current statistics from a specified source.
The main use of this command is to provide customer support a clone of your database so they can investigate performance issues related to the query optimizer. I am assuming this could be used internally as well to get a copy of a production and restore this database to a support server for troubleshooting as well. This might eliminate the need to take a native database backup of a large production database thus reducing the overall time, space, and complexity needed to troubleshoot certain issues in your production environment. Keep in mind there are certain restrictions and you need to be a member of the sysadmin fixed server role.
The main use of this command is to provide customer support a clone of your database so they can investigate performance issues related to the query optimizer. I am assuming this could be used internally as well to get a copy of a production and restore this database to a support server for troubleshooting as well. This might eliminate the need to take a native database backup of a large production database thus reducing the overall time, space, and complexity needed to troubleshoot certain issues in your production environment. Keep in mind there are certain restrictions and you need to be a member of the sysadmin fixed server role.
- DBCC CLONEDATABASE uses an internal database snapshot of the source database for the transactional consistency that is needed to perform the copy. This prevents blocking and concurrency problems when these commands are executed. If a snapshot cannot be created, DBCC CLONEDATABASE will fail.
See the online KB article https://support.microsoft.com/en-us/kb/3177838
I will be testing with some local databases to see how I can effectively leverage this snapshot but it looks promising and unless you happened to look at the SQL Server 2014 SP2 release notes you might have missed it.
Tuesday, July 19, 2016
Setting Min and Max SQL Server Memory Dynamically
Based off a standard configuration the goal is to set the min and max memory values via TSql script code.
You need to create the sp_configure statements as nvarchar variable because the syntax is incorrect when trying to execute them as part of a logic check
DECLARE @totalmemory BIGINT
DECLARE @max_memorysqlstmt NVARCHAR(500)
DECLARE @min_memorysqlstmt NVARCHAR(500)
SET @totalmemory = (SELECT CAST(physical_memory_kb as bigint) / POWER(1024, 2) FROM sys.dm_os_sys_info)
IF @totalmemory > = 256
BEGIN
PRINT 'Setting SQL Server memory to 256GB'
SET @min_memorysqlstmt = 'sp_configure ''min server memory'', 256000;'
SET @max_memorysqlstmt = 'sp_configure ''max server memory'', 256000;'
END
ELSE
BEGIN
PRINT 'Setting SQL Server memory to 10GB'
SET @min_memorysqlstmt = 'sp_configure ''min server memory'', 10240;'
SET @max_memorysqlstmt = 'sp_configure ''max server memory'', 10240;'
END
EXECUTE sp_executesql @max_memorysqlstmt
EXECUTE sp_executesql @min_memorysqlstmt
RECONFIGURE;
You need to create the sp_configure statements as nvarchar variable because the syntax is incorrect when trying to execute them as part of a logic check
DECLARE @totalmemory BIGINT
DECLARE @max_memorysqlstmt NVARCHAR(500)
DECLARE @min_memorysqlstmt NVARCHAR(500)
SET @totalmemory = (SELECT CAST(physical_memory_kb as bigint) / POWER(1024, 2) FROM sys.dm_os_sys_info)
IF @totalmemory > = 256
BEGIN
PRINT 'Setting SQL Server memory to 256GB'
SET @min_memorysqlstmt = 'sp_configure ''min server memory'', 256000;'
SET @max_memorysqlstmt = 'sp_configure ''max server memory'', 256000;'
END
ELSE
BEGIN
PRINT 'Setting SQL Server memory to 10GB'
SET @min_memorysqlstmt = 'sp_configure ''min server memory'', 10240;'
SET @max_memorysqlstmt = 'sp_configure ''max server memory'', 10240;'
END
EXECUTE sp_executesql @max_memorysqlstmt
EXECUTE sp_executesql @min_memorysqlstmt
RECONFIGURE;
Wednesday, June 8, 2016
Continuous Integration Visual Studio SSDT with Conditional Output
I am often asked how do you run
your database builds from Visual Studio with SSDT? Often times there is a requirement to use
MSBuild to complete the task of an integrated build solution and you want to perform different actions based on different project configurations. For example you might want to run some code table load scripts after the database is created or you need to move data from an old table to a new table or set of tables. To accomplish this you need to edit your SSDT project to enable different file contents to be copied and executed during the build and deployment of your project. Once the project is built the artifacts can be
deployed to various servers or packaged for later deployment as part of a
software package. All of this can be
accomplished with Visual Studio and SSDT along with MSBuild and some kind of
build orchestrator such as Jenkins.
The goal of this article is to
provide the framework within Visual Studio and SSDT to generate the desired output. Within Visual Studio SSDT the tool leverages a publishing model. This means that the build and deployment of the SSDT solution is run by clicking on the publishing action within a project or solution. But what if you want a build server to produce the artifacts for deploying your solution to a development server or as part of a deployment package to be installed at a later date? The idea is simple however getting it to all work together in Visual Studio can be a bit confusing. I will document the steps I needed to take to get this all working in Visual Studio 2015 SSDT. Note this will also work with previous version of Visual Studio however I would not go older than Visual Studio 2012.
To make this work you will be unloading and editing the project definition file (it is an xml file). I strongly suggest you have your project / solution in some sort of source code control system in the event you make a mistake and are unable to open the file.



To make this work you will be unloading and editing the project definition file (it is an xml file). I strongly suggest you have your project / solution in some sort of source code control system in the event you make a mistake and are unable to open the file.
Start by creating a new Visual
Studio database project (I will add mine to GIT later)
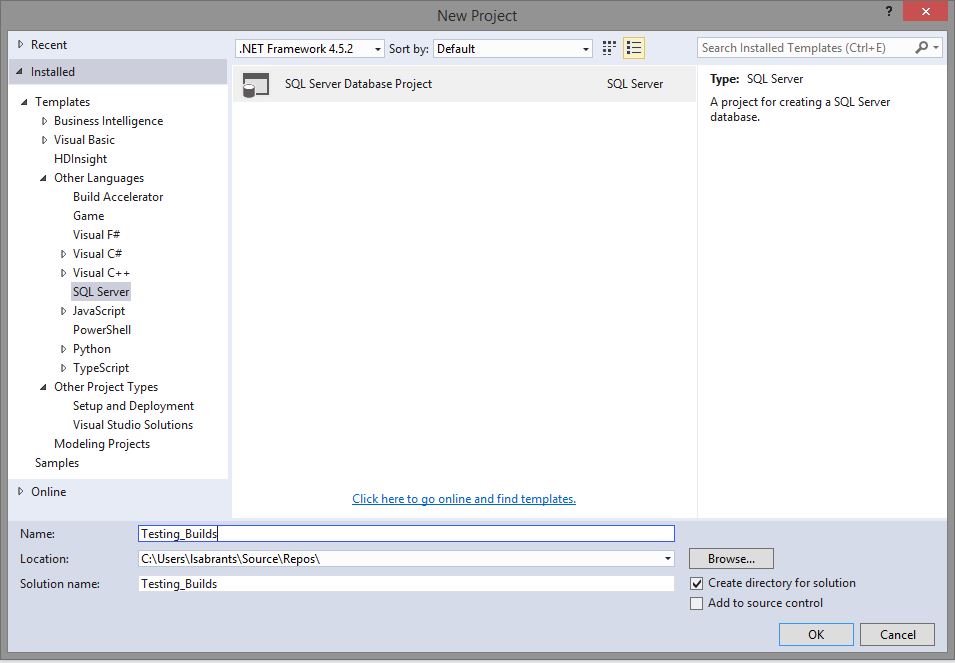
Here you can always
point to an existing database and import the objects into your current project
or start something from scratch.
I will just create a
couple of sample objects.
Visual Studio will
use a publish profile against a configuration when you publish. As a standard practice I always create a
build configuration that is more meaningful than the included ones.
For example I create
a Sandbox build configuration - I use this build configuration when I publish
locally. I also create some kind of
final release configuration. I will
create the Sandbox one here for illustration.
Now Right click on
the project and click the Publish option.
This will bring up a dialog box where you will enter values specific to
that environment. These are the
boilerplate options, any parameters and options you enter later on can be
passed in with MSBuild.
Save this profile in
the project for ease of use later on, I give them logical names, for example:
Sandbox.publish.xml
When Visual Studio
publishes a project it will also rely on Pre and Post deployment scripts. These scripts will executed in the Pre and
Post deployment events. You can do things
like populate code tables, drop old objects that you do not want to
automatically drop, make data changes, etc.
For today we will just execute a query that will select from the 1 table
I created.
So I create a set of
folders under a Scripts folder. These
folders will contain a set of special files that will have their Build Action
properties set. Name the folders Post-Deployment
and Pre-Deployment.
To get the process
to copy and move files depending on the build type specified we need to add a
few files to the following folders:
In the
Post-Deployment folder I create new script files and call them something like
Custom.Sandbox.PostDeployment.sql
Custom.Release.PostDeployment.sql
(If you need other
build configurations you would create additional files as needed to support the
other configurations)
What is important is
that you can tell which file is for a specific Build Configuration. If you wanted to do something in Sandbox but
not in Release the content of these files would be different.
In the
Pre-Deployment folder create files called
Custom.Sandbox.PreDeployment.sql
Custom.Release.PreDeployment.sq
I have added two
additional files to help with the demo.
Select_One.sql and Select_Two.sql
Each one of these
files will be executed based on the different configuration that is chosen so
we can see how our configurations are being applied.
Here is the content
of the Select_One.sql file
--
This is from the Select_One script code - it will just select 1.
SELECT
1 FROM dbo.SampleTable
Here is the content
of the Select_Two.sql file
--
This is from the Select_Two script code - it will just return A and B.
SELECT
'A' AS rSet
UNION
SELECT
'B' AS rSet
Now we will edit the
project file to enable the creation and copying of all the files during the
build.
Right click on the
project file and choose "Unload Project" Right click the unloaded project file and
select "Edit…"
We are going to add
a section to the project's XML file.
This will allow for copying the files over to the output during the
build from a configuration.




This is defining the actions to be taken during the build based on the configuration passed in. When you select Sandbox the build will take
our Custom.Release.PreDeployment and Custom.Release.PostDeployment files and copy
them over to the generic pre and post deployment files. So if you want to run some code as part of
the pre and/or post deployment the definition of what to run will be in there.
Once you are done
save the file and then Right click the project file and Reload it.
Now you can Right
click the project and say Build, take note of the project configuration you
have selected.
If you were able to
successfully build the project you can then go to the Post-deployment folder
and add the Script.PostDeployment.sql file by right clicking the folder and
saying Add Existing file -find the
Script.PostDeployment.sql and add it, do the same with the Pre-Deployment
folder.
It is important to
make sure you check the properties of these files. The property we are concerned with is the
Build Action property. For these two
files we want to make sure they are set to PostDeploy and PreDeploy (obviously
each based on the name). This tells the
build process to include these files as part of the output and when they should
be run
Remember that doing
something Pre-Deployment means that when you deploy this will be one of the
First things to happen. So if you need
to move data during a release from version to version you could do that here
before the objects are dropped in a Post-Deployment script.
Now to make it so
you can have custom actions based on a build configuration and based on Pre or
Post deployment events
edit the
Custom.Sandbox.PostDeployment.sql file and add the following:
":r
..\Select_One.sql" - without the
quotes
Save this file
This is a SQLCMD
that is telling the build process to move up one path and load up the contents
of the Select_One.sql file. This will
write the contents of this file inside the Script.PostDeployment.sql file. This is one of the files that SSDT will use
to create our final output script or to actually publish to a destination
server. The contents are also part of
the .dapac file that can also be later deployed using SQLCommand.exe.
Now click on the
Sandbox.publish.xml file and click Generate Script. In the output window you
should see the script that was created.
If you scroll down though the script you will see a bit of the magic. You should see the same code that is in the
Select_One.sql file!
"-- This is
from the Select_One script code - it will just select 1.
SELECT 1 FROM
dbo.SampleTable"

You can also make
changes to the Custom.Release.PostDeployment.sql file and add the following
":r
..\Select_Two.sql" - without the quotes
Save the file
Change your
configuration to Release and click on publish.
This will create a new publish file and will allow you to publish under
the current configuration. Click on
generate script. Browse the created
script file and towards the bottom you should see
"-- This is
from the Select_Two script code - it will just return A and B.
SELECT 'A' AS rSet
UNION
SELECT 'B' AS
rSet"

Once this script
file is executed it will run that code.
Now you have a
dynamic way to build your SSDT project file from MSBuild passing in a
configuration file and have the code execute exactly what you want when you
want it. This is very useful for loading
idempotent code table loads, moving data during deployments, cleaning up old
objects, etc.
Monday, May 23, 2016
New GIT Repo and code status Visual Studio 2015
For those of you using Visual Studio 2015 with SSDT and are managing your code with GIT a recent update brought a useful, but not easily noticed feature into the mix. You can now find a status bar located on the bottom of the window that provides some useful information at a glance. You can now see the repository name, the current branch name, number of pending updates to your project and the push status and count. This eliminates the need to switch to the Team Explore tab and navigate the menus to check stats and the like. Thanks Microsoft!Here you can see that I am connected to the HomeAuto repository and currently working on my development branch where I have 3 pending file changes.
I am not aware of the exact update where this was introduced but for the record I am running version 14.0.25123.00 Update 2.
Microsoft is doing a great job in integrating Visual Studio with various versions of source control products - particularly GIT - I.M.H.O.
Friday, November 13, 2015
Modifying Default Template For Stored Procedures in Visual Studio 2015 SSDT
I have always found
it very useful to create database coding standards and making it very easy for
myself and others to apply those standards is critical, one of those standards
is applying a default comment header block to SQL Server Stored Procedures.
In previous versions
of Visual Studio I found it very handy to create a procedure template for new
stored procedure creation and distribute that temple to my team members for
easy implementation. In Visual Studio SSDT
(SQL Server Data Tools) when adding a new stored procedure to a database
project, Visual Studio derives a default stored procedure from a template file.
Here is a sample of
what I like to see each time a procedure is created

The scaffolding code
is generated from a template located here
C:\Program Files
(x86)\Microsoft Visual Studio
14.0\Common7\IDE\Extensions\Microsoft\SQLDB\Extensions\SqlServer\Items
NOTE: This path is
very specific to Visual Studio 2015 SSDT.
The files Create
Procedure.sql and Create Procedure.vstemplate are what do the magic. Make sure you make a backup of the Create
Procedure.sql file for safe keeping.
Edit the Create
Procedure.sql file and include any comment text or other common items you find
yourself typing each time you create a procedure. For example BEGIN and END statements, setting
NOCOUNT ON; NOCOUNT OFF;, etc.
Because of
permission issues save this modified file to a DIFFERENT folder
Now delete the
original file from the Visual Studio path
Copy the file
modified file back into the directory
Restart Visual
Studio
Now each time you
create a new stored procedure your boilerplate code will be waiting for
you.
Subscribe to:
Comments (Atom)